Classes | |
| class | ConfigParamsList |
| class | DataReplacementConstants |
| class | ExceptionLog |
| class | InterruptableThread |
| class | JsonSerializable |
| class | LoggerFileName |
| class | MLStripper |
| class | MPLogger |
| class | PathMaker |
| class | PropertiesValidator |
| class | SQLExpression |
| class | UrlNormalizator |
| class | UrlParser |
Functions | |
| def | getPath (dictionary, jsonString, path) |
| def | getConfigParameter (parser, section, option, defValue) |
| def | getTracebackInfo (linesNumberMax=None) |
| def | tracefunc (frame, event, arg, indent=None) |
| def | varDump (obj, stringify=True, strTypeMaxLen=256, strTypeCutSuffix='...', stringifyType=1, ignoreErrors=False, objectsHash=None, depth=0, indent=2, ensure_ascii=False, maxDepth=10) |
| def | memUsage (point="") |
| def | urlNormalization (base, url, supportProtocols=None, log=None) |
| def | storePickleOnDisk (input_pickled_object, env_path, file_name) |
| def | urinormpath (path, stripWWW=False, useValidator=False, enableAdditionNormalize=True) |
| def | loggerFlush (loggerObj) |
| def | accumulateSubstrings (substrList, prefixes) |
| def | generateReplacementDict () |
| def | parseHost (url) |
| def | convertToHttpDateFmt (date_str) |
| def | autoFillSiteId (siteId, log) |
| def | stripHTMLComments (htmlBuf=None, soup=None, hType=3) |
| def | cutSubstringEntrances (buf, startStr='<!--', finishStr='-->', behaveMask=0, greediness=0, finishDefault='\n') |
| def | eraseNoScript (htmlBuf=None) |
| def | stripHTMLTags (htmlTxt, method=0, joinGlue=' ', regExp=None) |
| def | innerHTMLText (htmlBuf, stripComment=True, stripScript=True) |
| def | innerText (selectorList, delimiter=' ', innerDelimiter=' ', tagReplacers=None, REconditions=None, attrConditions=None, keepAttributes=None, baseUrl=None, closeVoid=None, excludeNodes=None) |
| def | innerTextToList (selectorList, delimiter=' ', innerDelimiter=' ', tagReplacers=None, REconditions=None, attrConditions=None, keepAttributes=None, baseUrl=None, closeVoid=None, excludeNodes=None) |
| def | getFirstNotEmptySubXPath (xpath, sel, subXPathPattern, subXPathes) |
| def | getPairsDicts (incomeDict, splitters=') |
| def | splitPairs (buf, splitters=') |
| def | isTailSubstr (str1, str2) |
| def | replaceLoopValue (buf, replaceFrom, replaceTo) |
| def | getHTMLRedirectUrl (buff, log) |
| def | emailParse (href, onlyName=False, defaultSeparator=' ') |
| def | strToUnicode (inputStr) |
| def | removeDuplicated (inStr, delimiter="\, joingGlue=None, trimMode=1, skipEmpty=False) |
| def | getContentCSSMarkupEntrancesNumber (content) |
| def | executeWithTimeout (func, args=None, kwargs=None, timeout=1, default=None, log=None) |
| def | loadFromFileByReference (fileReference, initString=None, protocolPrefix='file://', loggerObj=None) |
| def | readFile (inFile, decodeUTF8=True) |
| def | escape (string) |
| def | isValidURL (url) |
| def | getHash (strBuf, binSize=32, digestType=0, fixedMode=0, valLimit=18446744073709552000L) |
| def | strToFloat (val, defaultValue=0.0, log=None, positivePrefixes=None) |
| def | strToProxy (proxyString, log=None, defaultProxyType='http') |
| def | executeCommand (cmd, inputStream='', log=None) |
| def | jsonLoadsSafe (jsonString, default=None, log=None) |
| def | reMatch (word, buff, log=None) |
Detailed Description
Created on Mar 28, 2014 @package: app @author: scorp @link: http://hierarchical-cluster-engine.com/ @copyright: Copyright © 2013-2014 IOIX Ukraine @license: http://hierarchical-cluster-engine.com/license/ @since: 0.1
Function Documentation
◆ accumulateSubstrings()
| def app.Utils.accumulateSubstrings | ( | substrList, | |
| prefixes | |||
| ) |
Definition at line 905 of file Utils.py.
◆ autoFillSiteId()
◆ convertToHttpDateFmt()
◆ cutSubstringEntrances()
| def app.Utils.cutSubstringEntrances | ( | buf, | |
startStr = '<!--', |
|||
finishStr = '-->', |
|||
behaveMask = 0, |
|||
greediness = 0, |
|||
finishDefault = '\n' |
|||
| ) |
Definition at line 1011 of file Utils.py.

◆ emailParse()
| def app.Utils.emailParse | ( | href, | |
onlyName = False, |
|||
defaultSeparator = ' ' |
|||
| ) |
Definition at line 1302 of file Utils.py.
◆ eraseNoScript()
| def app.Utils.eraseNoScript | ( | htmlBuf = None | ) |
Definition at line 1046 of file Utils.py.

◆ escape()
| def app.Utils.escape | ( | string | ) |
◆ executeCommand()
| def app.Utils.executeCommand | ( | cmd, | |
inputStream = '', |
|||
log = None |
|||
| ) |
◆ executeWithTimeout()
| def app.Utils.executeWithTimeout | ( | func, | |
args = None, |
|||
kwargs = None, |
|||
timeout = 1, |
|||
default = None, |
|||
log = None |
|||
| ) |
Definition at line 1544 of file Utils.py.

◆ generateReplacementDict()
◆ getConfigParameter()
| def app.Utils.getConfigParameter | ( | parser, | |
| section, | |||
| option, | |||
| defValue | |||
| ) |
Definition at line 200 of file Utils.py.
◆ getContentCSSMarkupEntrancesNumber()
| def app.Utils.getContentCSSMarkupEntrancesNumber | ( | content | ) |
Definition at line 1426 of file Utils.py.
◆ getFirstNotEmptySubXPath()
| def app.Utils.getFirstNotEmptySubXPath | ( | xpath, | |
| sel, | |||
| subXPathPattern, | |||
| subXPathes | |||
| ) |
Definition at line 1174 of file Utils.py.
◆ getHash()
| def app.Utils.getHash | ( | strBuf, | |
binSize = 32, |
|||
digestType = 0, |
|||
fixedMode = 0, |
|||
valLimit = 18446744073709552000L |
|||
| ) |
Definition at line 1649 of file Utils.py.
◆ getHTMLRedirectUrl()
| def app.Utils.getHTMLRedirectUrl | ( | buff, | |
| log | |||
| ) |
Definition at line 1278 of file Utils.py.

◆ getPairsDicts()
| def app.Utils.getPairsDicts | ( | incomeDict, | |
splitters = ' |
|||
| ) |

◆ getPath()
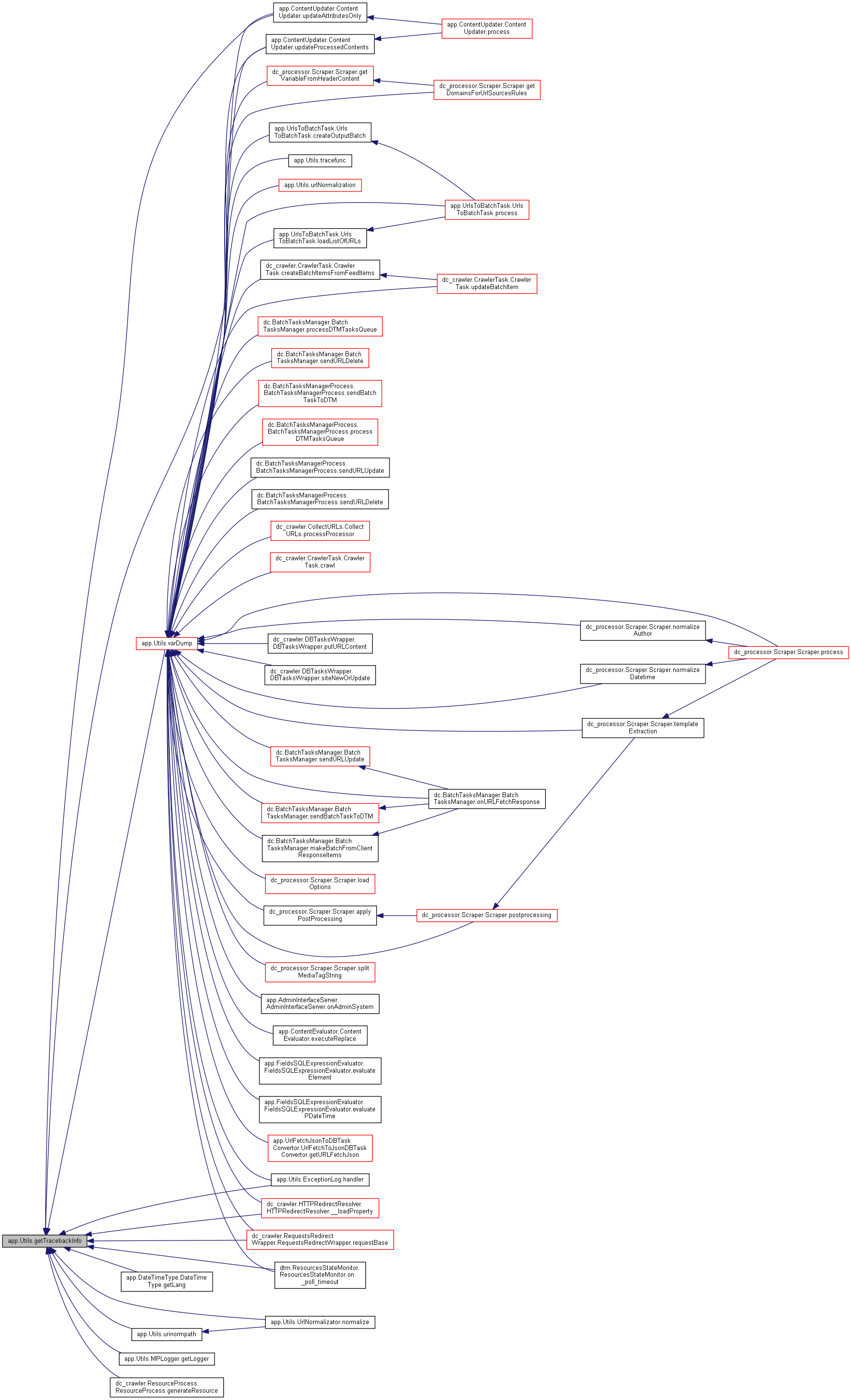
◆ getTracebackInfo()
| def app.Utils.getTracebackInfo | ( | linesNumberMax = None | ) |
◆ innerHTMLText()
| def app.Utils.innerHTMLText | ( | htmlBuf, | |
stripComment = True, |
|||
stripScript = True |
|||
| ) |
Definition at line 1130 of file Utils.py.

◆ innerText()
| def app.Utils.innerText | ( | selectorList, | |
delimiter = ' ', |
|||
innerDelimiter = ' ', |
|||
tagReplacers = None, |
|||
REconditions = None, |
|||
attrConditions = None, |
|||
keepAttributes = None, |
|||
baseUrl = None, |
|||
closeVoid = None, |
|||
excludeNodes = None |
|||
| ) |


◆ innerTextToList()
| def app.Utils.innerTextToList | ( | selectorList, | |
delimiter = ' ', |
|||
innerDelimiter = ' ', |
|||
tagReplacers = None, |
|||
REconditions = None, |
|||
attrConditions = None, |
|||
keepAttributes = None, |
|||
baseUrl = None, |
|||
closeVoid = None, |
|||
excludeNodes = None |
|||
| ) |
Definition at line 1160 of file Utils.py.

◆ isTailSubstr()
◆ isValidURL()
| def app.Utils.isValidURL | ( | url | ) |

◆ jsonLoadsSafe()
| def app.Utils.jsonLoadsSafe | ( | jsonString, | |
default = None, |
|||
log = None |
|||
| ) |
Definition at line 1783 of file Utils.py.
◆ loadFromFileByReference()
| def app.Utils.loadFromFileByReference | ( | fileReference, | |
initString = None, |
|||
protocolPrefix = 'file://', |
|||
loggerObj = None |
|||
| ) |
Definition at line 1595 of file Utils.py.

◆ loggerFlush()
| def app.Utils.loggerFlush | ( | loggerObj | ) |
◆ memUsage()
◆ parseHost()
| def app.Utils.parseHost | ( | url | ) |

◆ readFile()
| def app.Utils.readFile | ( | inFile, | |
decodeUTF8 = True |
|||
| ) |

◆ reMatch()
| def app.Utils.reMatch | ( | word, | |
| buff, | |||
log = None |
|||
| ) |
◆ removeDuplicated()
| def app.Utils.removeDuplicated | ( | inStr, | |
delimiter = "\n", |
|||
joingGlue = None, |
|||
trimMode = 1, |
|||
skipEmpty = False |
|||
| ) |
Definition at line 1394 of file Utils.py.
◆ replaceLoopValue()
| def app.Utils.replaceLoopValue | ( | buf, | |
| replaceFrom, | |||
| replaceTo | |||
| ) |
Definition at line 1233 of file Utils.py.
◆ splitPairs()
| def app.Utils.splitPairs | ( | buf, | |
splitters = ' |
|||
| ) |

◆ storePickleOnDisk()
| def app.Utils.storePickleOnDisk | ( | input_pickled_object, | |
| env_path, | |||
| file_name | |||
| ) |
Definition at line 754 of file Utils.py.
◆ stripHTMLComments()
| def app.Utils.stripHTMLComments | ( | htmlBuf = None, |
|
soup = None, |
|||
hType = 3 |
|||
| ) |
Definition at line 982 of file Utils.py.


◆ stripHTMLTags()
| def app.Utils.stripHTMLTags | ( | htmlTxt, | |
method = 0, |
|||
joinGlue = ' ', |
|||
regExp = None |
|||
| ) |
Definition at line 1064 of file Utils.py.
◆ strToFloat()
| def app.Utils.strToFloat | ( | val, | |
defaultValue = 0.0, |
|||
log = None, |
|||
positivePrefixes = None |
|||
| ) |
Definition at line 1683 of file Utils.py.
◆ strToProxy()
| def app.Utils.strToProxy | ( | proxyString, | |
log = None, |
|||
defaultProxyType = 'http' |
|||
| ) |
Definition at line 1710 of file Utils.py.

◆ strToUnicode()
| def app.Utils.strToUnicode | ( | inputStr | ) |
◆ tracefunc()
| def app.Utils.tracefunc | ( | frame, | |
| event, | |||
| arg, | |||
indent = None |
|||
| ) |

◆ urinormpath()
| def app.Utils.urinormpath | ( | path, | |
stripWWW = False, |
|||
useValidator = False, |
|||
enableAdditionNormalize = True |
|||
| ) |
Definition at line 764 of file Utils.py.


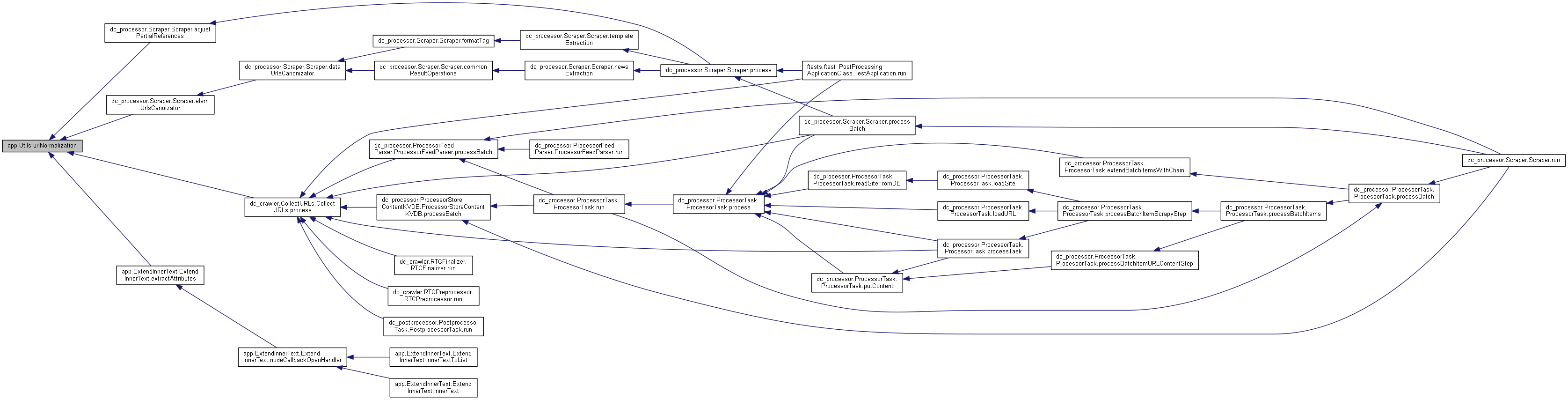
◆ urlNormalization()
| def app.Utils.urlNormalization | ( | base, | |
| url, | |||
supportProtocols = None, |
|||
log = None |
|||
| ) |
Definition at line 561 of file Utils.py.

◆ varDump()
| def app.Utils.varDump | ( | obj, | |
stringify = True, |
|||
strTypeMaxLen = 256, |
|||
strTypeCutSuffix = '...', |
|||
stringifyType = 1, |
|||
ignoreErrors = False, |
|||
objectsHash = None, |
|||
depth = 0, |
|||
indent = 2, |
|||
ensure_ascii = False, |
|||
maxDepth = 10 |
|||
| ) |
Definition at line 410 of file Utils.py.

Variable Documentation
◆ lock
◆ logger
| app.Utils.logger = logging.getLogger(APP_CONSTS.LOGGER_NAME) |
◆ META_REDIRECT
| string app.Utils.META_REDIRECT = r"http-equiv\W*refresh.+?url\W+?(.+?)\"" |
◆ SEARCH_COMMENT_PATTERN
| string app.Utils.SEARCH_COMMENT_PATTERN = r"<![ \r\n\t]*(--([^\-]|[\r\n]|-[^\-])*--[ \r\n\t]*)>" |
◆ SEARCH_COMMENT_SIMPLE_PATTERN
| string app.Utils.SEARCH_COMMENT_SIMPLE_PATTERN = r"<!--(.|\n)*?-->" |
◆ SEARCH_NOSCRIPT_PATTERN
| string app.Utils.SEARCH_NOSCRIPT_PATTERN = r"<noscript>(.|\n)*?</noscript>" |
◆ tracebackElapsedTimeDelimiter
◆ tracebackElapsedTimeFormat
◆ tracebackExcludeFunctionName
◆ tracebackExcludeFunctionNameStarts
◆ tracebackExcludeModulePath
| list app.Utils.tracebackExcludeModulePath = ["/usr/lib/", "/usr/local/lib/"] |
◆ tracebackFunctionNameDelimiter
◆ tracebackIdent
◆ tracebackIdentFiller
◆ tracebackIncludeArg
◆ tracebackIncludeArgPrefix
◆ tracebackIncludeExitCalls
◆ tracebackIncludeFileNumber
◆ tracebackIncludeFileNumberDelimiter
◆ tracebackIncludeInternalCalls
◆ tracebackIncludeLineNumber
◆ tracebackIncludeLineNumberDelimiter
◆ tracebackIncludeLocals
◆ tracebackIncludeLocalsPrefix
| string app.Utils.tracebackIncludeLocalsPrefix = "\nLOCALS:\n" |
◆ tracebackList
◆ tracebackLogger
◆ tracebackMessageCall
◆ tracebackmessageDelimiter
◆ tracebackMessageExit
◆ tracebackRecursionlimit
◆ tracebackRecursionlimitErrorMsg
| string app.Utils.tracebackRecursionlimitErrorMsg = "RECURSION STACK LIMIT REACHED " |
◆ tracebackTimeMark
◆ tracebackTimeMarkDelimiter
◆ tracebackTimeMarkFormat
| string app.Utils.tracebackTimeMarkFormat = "%Y-%m-%d %H:%M:%S.%f" |
◆ tracebackTimeQueue
◆ tracebackUnknownExceptionMsg
- Generated on Fri Nov 24 2017 18:54:20 for HCE Project Python language Distributed Tasks Manager Application, Distributed Crawler Application and client API bindings. by
 1.8.13
1.8.13