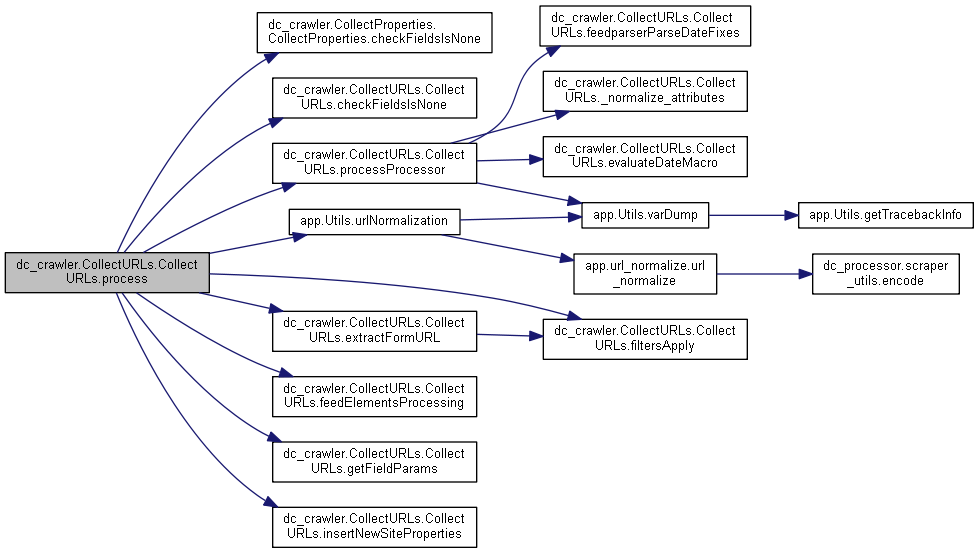
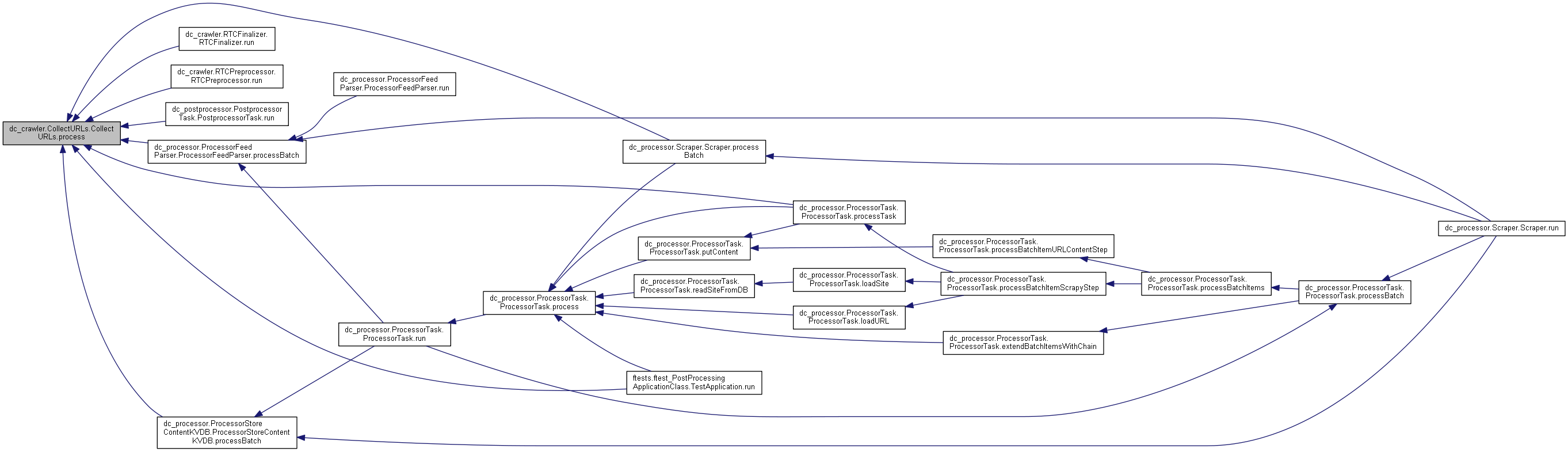
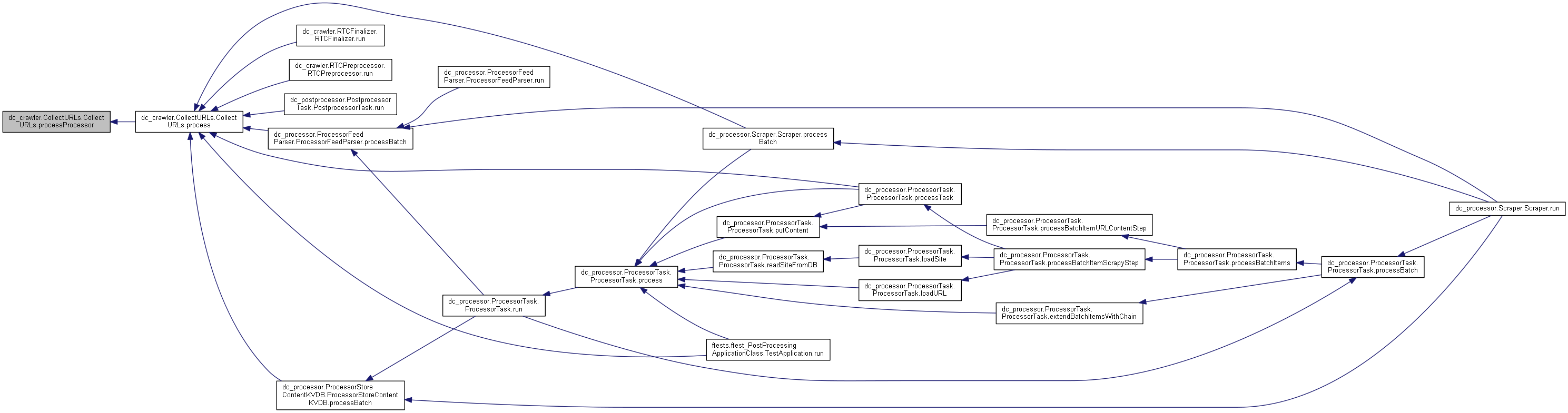
92 def process(self, httpCode, readOnly=False, httpApplyHeaders=None, proxyName=None):
94 self.checkFieldsIsNone()
95 if self.siteProperties
is None:
96 self.siteProperties = {}
97 if self.processContentTypes
is None:
98 self.processContentTypes = []
99 localSiteId = self.batchItem.siteId
if self.batchItem.siteId
else "0" 102 internalLinks, externalLinks = [], []
111 logger.debug(
"!!! self.site.maxURLsFromPage = " + str(self.site.maxURLsFromPage))
112 logger.debug(
"!!! self.url.maxURLsFromPage = " + str(self.url.maxURLsFromPage))
114 if self.site
is not None and self.site.maxURLsFromPage
is not None:
115 maxURLsFromPage = self.site.maxURLsFromPage
117 if self.url
is not None and self.url.maxURLsFromPage
is not None and self.url.maxURLsFromPage > 0:
118 maxURLsFromPage = self.url.maxURLsFromPage
120 if nextStep
and self.crawledResource
is not None and \
121 not self.BINARY_CONTENT_TYPE_PATTERN.search(self.crawledResource.content_type):
125 if nextStep
and self.crawledResource
is not None:
126 code_type = int(self.crawledResource.http_code) / 100
127 if code_type == 4
or code_type == 5:
130 if nextStep
and self.crawledResource
is not None and not self.crawledResource.html_content:
139 if self.dom
is not None:
140 self.processProcessor(urlSet, self.dom, self.urlXpathList, self.batchItem.urlObj)
141 formUrls, formMethods, formFields = self.extractFormURL(self.dom, self.siteProperties)
142 urlSet.update(formUrls)
144 logger.debug(
"DOM is None")
146 if self.url.type == dc.EventObjects.URL.TYPE_SINGLE:
147 logger.debug(
"URL type: single")
150 if nextStep
and self.crawledResource.dynamic_fetcher_result_type == \
151 SeleniumFetcher.MACRO_RESULT_TYPE_URLS_LIST:
154 ul = json.loads(self.crawledResource.html_content)
155 except Exception, err:
156 logger.error(
"Error deserialize macro data from result string: %s\n%s", str(err),
157 self.crawledResource.html_content)
159 logger.debug(
"Fill urlSet from macro results: %s items", str(len(ul)))
160 if isinstance(ul, list):
161 urlSet.update([u
for u
in ul
if isinstance(u, basestring)
and u !=
''])
164 if self.url.type == dc.EventObjects.URL.TYPE_CHAIN:
165 logger.debug(
"URL type: chain")
170 urlTable = self.DC_URLS_TABLE_PREFIX + localSiteId
171 self.urlProcess.urlTable = urlTable
173 if self.siteProperties
is not None and "RSS_FEED_ZERO_ITEM" in self.siteProperties
and \
174 int(self.siteProperties[
"RSS_FEED_ZERO_ITEM"]) == 1:
175 if self.processorName == PCONSTS.PROCESSOR_FEED_PARSER
or self.processorName == PCONSTS.PROCESSOR_RSS:
176 self.feedElementsProcessing(self.url.urlMd5, httpCode, self.url.url, localSiteId, self.url, self.url.url,
177 params, maxURLsFromPage,
True)
179 logger.debug(
">>> Wrong \"RSS_FEED_ZERO_ITEM\" property's value")
181 logger.debug(
"URLs candidates collected %s items:\n%s", str(len(urlSet)), str(urlSet))
183 if self.site.maxURLs > 0
and len(urlSet) >= self.site.maxURLs:
184 urlSet = set(list(urlSet)[:self.site.maxURLs])
185 logger.debug(
"Site maxURLs = %s limit reached.", str(self.site.maxURLs))
187 if self.site.maxResources > 0
and len(urlSet) >= self.site.maxResources:
188 urlSet = set(list(urlSet)[:self.site.maxResources])
189 logger.debug(
"Site maxResources = %s limit reached.", str(self.site.maxResources))
193 for elemUrl
in urlSet:
195 if self.isAbortedByTTL():
196 logger.debug(
"Aborted by TTL. All elements skipped.")
200 logger.debug(
"Some url from urlSet is None, skipped.")
203 elemUrl = elemUrl.strip()
205 logger.debug(
"Some url from urlSet is empty, skipped!")
209 self.urlProcess.urlObj = self.url
210 self.urlProcess.url = elemUrl
211 self.urlProcess.dbWrapper = self.dbWrapper
212 self.urlProcess.siteId = localSiteId
213 retUrl, retContinue = self.urlProcess.processURL(self.realUrl, internalLinks, externalLinks, self.filtersApply,
215 if retUrl
is not None:
217 elemUrl = UrlNormalize.execute(siteProperties=self.siteProperties, base=self.baseUrl, url=elemUrl, supportProtocols=
None, log=logger)
222 logger.debug(
"Candidate URL is not passed general checks, skipped: %s", str(elemUrl))
226 if not self.filtersApply(inputFilters=self.site.filters,
228 depth=self.url.depth,
229 wrapper=self.dbWrapper,
231 logger.debug(
"Candidate URL not matched filters, skipped.")
234 logger.debug(
"Candidate URL matched filters.")
237 urlMd5 = hashlib.md5(elemUrl).hexdigest()
238 self.urlProcess.url = elemUrl
239 self.urlProcess.siteId = localSiteId
240 self.urlProcess.urlTable = urlTable
241 if self.urlProcess.isUrlExist(self.site.recrawlPeriod, urlMd5):
242 logger.debug(
"Candidate URL %s already exist, skipped.", str(urlMd5))
245 if self.site.maxURLs > 0:
246 if httpCode == CRAWLER_CONSTS.HTTP_CODE_200:
251 if self.dbWrapper
is not None:
252 currentCnt = self.urlProcess.readCurrentCnt(self.site.maxURLs)
253 if currentCnt >= self.site.maxURLs
or countCnt >= self.site.maxURLs
or \
254 (countCnt + countErrors) >= self.site.maxURLs:
255 logger.debug(
"Site MaxURLs: %s limit is reached. countCnt = %s, currentCnt = %s",
256 str(self.site.maxURLs), str(countCnt), str(currentCnt))
257 autoremovedURLs = self.urlProcess.autoRemoveURL(self.autoRemoveProps, self.site.recrawlPeriod, urlTable,
259 if autoremovedURLs == 0:
260 logger.debug(
"No one URL auto removed, candidate URL skipped!")
263 logger.debug(
"%s URLs auto removed.", str(autoremovedURLs))
265 if currentCnt >= self.site.maxResources
or countCnt >= self.site.maxResources
or \
266 (countCnt + countErrors) >= self.site.maxResources:
267 logger.debug(
"Site maxResources = %s limit is reached. countCnt = %s, currentCnt = %s",
268 str(self.site.maxResources), str(countCnt), str(currentCnt))
269 autoremovedURLs = self.urlProcess.autoRemoveURL(self.autoRemoveProps, self.site.recrawlPeriod, urlTable,
271 if autoremovedURLs == 0:
272 logger.debug(
"No one URL auto removed, candidate URL skipped!")
275 logger.debug(
"%s URLs auto removed.", str(autoremovedURLs))
280 if self.autoDetectMime == self.DETECT_MIME_COLLECTED_URL
and self.processContentTypes
is not None:
281 self.urlProcess.url = elemUrl
282 detectedMime = self.urlProcess.detectUrlMime(self.siteProperties[
"CONTENT_TYPE_MAP"]
if \
283 "CONTENT_TYPE_MAP" in self.siteProperties
else None)
284 if detectedMime
not in self.processContentTypes:
285 logger.debug(
"Candidate URL MIME type is not matched, skipped!")
289 if "ROBOTS_COLLECT" not in self.siteProperties
or int(self.siteProperties[
"ROBOTS_COLLECT"]) > 0:
290 logger.debug(
"Robots.txt obey mode is ON")
291 if self.robotsParser
and self.robotsParser.loadRobots(elemUrl, self.batchItem.siteId, httpApplyHeaders,
293 isAllowed, retUserAgent = self.robotsParser.checkUrlByRobots(elemUrl, self.batchItem.siteId,
296 logger.debug(
"URL " + elemUrl +
" is NOT Allowed by user-agent:" + str(retUserAgent))
297 self.urlProcess.updateURLForFailed(APP_CONSTS.ERROR_ROBOTS_NOT_ALLOW, self.batchItem)
300 self.urlProcess.siteId = localSiteId
301 depth = self.urlProcess.getDepthFromUrl(self.batchItem.urlId)
304 if "HTTP_REDIRECT_RESOLVER" in self.siteProperties
and self.siteProperties[
"HTTP_REDIRECT_RESOLVER"] !=
"":
305 logger.debug(
'!!!!!! HTTP_REDIRECT_RESOLVER !!!!! ')
308 if "CONNECTION_TIMEOUT" in self.siteProperties:
309 connectionTimeout = float(self.siteProperties[
"CONNECTION_TIMEOUT"])
311 connectionTimeout = CRAWLER_CONSTS.CONNECTION_TIMEOUT
313 tm = int(self.url.httpTimeout) / 1000.0
314 if isinstance(self.url.httpTimeout, float):
315 tm += float(
'0' + str(self.url.httpTimeout).strip()[str(self.url.httpTimeout).strip().find(
'.'):])
317 proxies = {
"http":
"http://" + proxyName}
if proxyName
is not None else None 320 if 'HTTP_AUTH_NAME' in self.siteProperties
and 'HTTP_AUTH_PWD' in self.siteProperties:
321 authName = self.siteProperties[
'HTTP_AUTH_NAME']
322 authPwd = self.siteProperties[
'HTTP_AUTH_PWD']
323 if authName
is not None and authPwd
is not None:
324 auth = (authName, authPwd)
327 for key
in self.siteProperties.keys():
328 if key.startswith(
'HTTP_POST_FORM_'):
329 postForms[key[len(
'HTTP_POST_FORM_'):]] = self.siteProperties[key]
330 postData = self.urlProcess.resolveHTTP(postForms, httpApplyHeaders)
332 maxRedirects = HTTPRedirectResolver.RedirectProperty.DEFAULT_VALUE_MAX_REDIRECTS
333 if 'HTTP_REDIRECTS_MAX' in self.siteProperties:
334 maxRedirects = int(self.siteProperties[
'HTTP_REDIRECTS_MAX'])
336 redirectResolver = HTTPRedirectResolver(propertyString=self.siteProperties[
"HTTP_REDIRECT_RESOLVER"],
337 fetchType=self.site.fetchType,
338 dbWrapper=self.dbWrapper,
340 connectionTimeout=connectionTimeout)
342 resUrl = redirectResolver.resolveRedirectUrl(url=elemUrl,
343 headers=httpApplyHeaders,
349 maxRedirects=maxRedirects,
350 filters=self.site.filters)
352 logger.debug(
"Resolved url: %s", str(resUrl))
355 if elemUrl
is not None:
356 self.urlProcess.url = elemUrl
357 self.urlProcess.siteId = localSiteId
358 self.urlProcess.urlObj = self.url
359 localUrlObj = self.urlProcess.createUrlObjForCollectURLs(urlMd5, formMethods, self.batchItem.urlId, depth,
360 detectedMime, self.site.maxURLsFromPage)
362 localUrlObj.linksI = len(internalLinks)
363 localUrlObj.linksE = len(externalLinks)
365 if self.processorName == PCONSTS.PROCESSOR_FEED_PARSER
or self.processorName == PCONSTS.PROCESSOR_RSS:
366 self.feedElementsProcessing(urlMd5, httpCode, elemUrl, localSiteId, localUrlObj, localUrl, params,
369 params.append(localUrlObj)
371 if useChains
and "URL_CHAIN" in self.siteProperties
and self.siteProperties[
"URL_CHAIN"]
is not None:
372 localChainDict = json.loads(self.siteProperties[
"URL_CHAIN"])
373 depth = self.urlProcess.getDepthFromUrl(self.batchItem.urlId)
374 if "url_pattern" in localChainDict:
375 for elemUrl
in urlSet:
377 logger.debug(
"Some url from urlSet is None")
379 self.urlProcess.url = elemUrl
385 logger.debug(
"Bad url normalization, url: %s", retUrl)
390 if self.autoDetectMime == self.DETECT_MIME_COLLECTED_URL
and self.processContentTypes
is not None:
391 self.urlProcess.url = elemUrl
392 detectedMime = self.urlProcess.detectUrlMime(self.siteProperties[
"CONTENT_TYPE_MAP"]
if \
393 "CONTENT_TYPE_MAP" in self.siteProperties
else None, \
394 self.batchItem.urlObj)
395 urlMd5 = hashlib.md5(elemUrl).hexdigest()
396 self.urlProcess.url = elemUrl
397 self.urlProcess.siteId = localSiteId
398 self.urlProcess.urlObj = self.url
400 localUrlObj = self.urlProcess.\
401 createUrlObjForChain(localChainDict[
"url_pattern"], urlMd5, formMethods,
402 self.batchItem.urlId, depth, detectedMime, self.site.maxURLsFromPage)
403 if localUrlObj
is not None:
404 chainUrls.append(copy.deepcopy(localUrlObj))
405 except Exception
as excp:
406 logger.error(
"Error in URL_CHAIN deserialize, excp = " + str(excp))
407 if len(urlSet) > 0
and len(params) == 0:
408 logger.debug(
"Zero urls are collected for len(urlSet): %s", str(len(urlSet)))
409 elif len(params) > 0:
410 logger.debug(
"Collected and send to insert as new: %s", str(len(urlSet)))
413 if self.dbWrapper
is not None:
414 self.dbWrapper.urlNew(params)
415 self.dbWrapper.urlNew(chainUrls)
416 self.urlProcess.updateTypeForURLObjects(chainUrls)
417 self.dbWrapper.collectedURLsRecalculating(localSiteId)
419 if formFields
is not None and self.postForms
is not None and self.dbWrapper
is not None:
420 fieldParams = self.getFieldParams(formFields, self.postForms, localSiteId)
421 self.insertNewSiteProperties(fieldParams, self.dbWrapper, localSiteId)
426 return nextStep, internalLinks, externalLinks, params, self.feedItems, chainUrls
def urlNormalization(base, url, supportProtocols=None, log=None)

 1.8.13
1.8.13