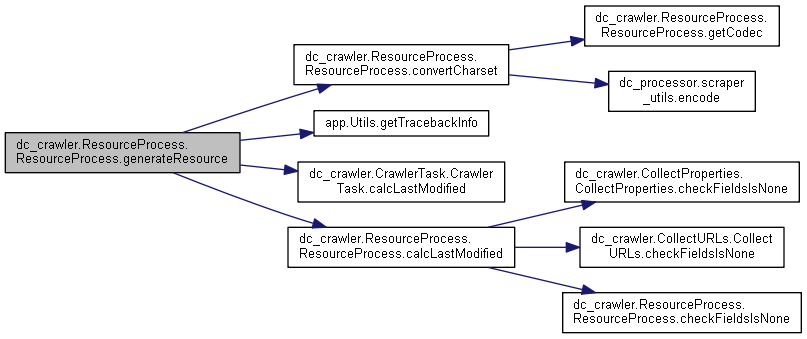
107 def generateResource(self, startTime, res, headers, crawledTime, defaultIcrCrawlTime, contentTypeMap=None):
109 resource = CrawledResource()
110 resource.meta_content = res.meta_res
111 resource.crawling_time = int((crawledTime - startTime) * 1000)
112 if res.content_size
is not None and resource.crawling_time != 0:
113 resource.bps = res.content_size / resource.crawling_time * 1000
115 logger.info(
"crawling_time: %s, bps: %s", resource.crawling_time, resource.bps)
116 resource.http_code = res.status_code
117 logger.debug(
"headers is :%s", res.headers)
119 if res.headers
is not None:
120 for elem
in res.headers:
121 localHeaders[elem.lower()] = res.headers[elem]
123 logger.debug(
"!!! localHeaders = %s", str(localHeaders))
124 logger.debug(
"!!! localHeaders.get('content-type', '') = %s", str(localHeaders.get(
'content-type',
'')))
127 resource.content_type = localHeaders.get(
'content-type',
'text/xml').split(
';')[0]
130 resource.cookies = res.cookies
133 logger.debug(
"!!! res.encoding = '%s'", str(res.encoding))
134 if isinstance(res.encoding, basestring):
135 resource.charset = res.encoding.split(
',')[0]
137 resource.charset = res.encoding
139 resource.charset =
"utf-8" 141 if res.request
is not None and hasattr(res.request,
'headers')
and res.request.headers
is not None:
142 resource.html_request =
'\r\n'.
join([
'%s: %s' % (k, v)
for k, v
in res.request.headers.iteritems()])
143 elif res.request
is not None and isinstance(res.request, dict)
and 'headers' in res.request
and\
144 res.request[
'headers']
is not None:
145 resource.html_request =
'\r\n'.
join([
'%s: %s' % (k, v)
for k, v
in res.request[
'headers'].iteritems()])
147 resource.html_request =
"" 149 if res.headers
is not None:
151 resource.response_header = self.convertCharset(res.headers, resource.charset)
152 except Exception, err:
153 logger.error(str(err))
156 resource.last_modified = self.calcLastModified(resource, res, defaultIcrCrawlTime)
158 if contentTypeMap
is not None and resource.content_type
in contentTypeMap:
159 logger.debug(
">>> Mime type replaced from %s to %s", resource.content_type, contentTypeMap[resource.content_type])
160 resource.content_type = copy.deepcopy(contentTypeMap[resource.content_type])
161 logger.debug(
"request is: %s", resource.html_request)
162 logger.debug(
"response is: %s", resource.response_header)
def getTracebackInfo(linesNumberMax=None)










 1.8.13
1.8.13