Public Member Functions | |
| def | __init__ (self, protocols=None) |
| def | setProtocols (self, protocols=None) |
| def | checkUrlByPath (self, url) |
| def | checkUrlByProtocol (self, url) |
| def | checkFieldsIsNone (self, checkList) |
| def | resolveTableName (self, localSiteId) |
| def | readCurrentCnt (self, maxURLs) |
| def | simpleURLCanonize (self, realUrl) |
| def | processURL (self, realUrl, internalLinks, externalLinks, filtersApply=None, siteFilters=None, baseUrl=None) |
| def | isUrlExist (self, recrawlPeriod, urlMd5) |
| def | updateURLFields (self, urlMd5, wrapper, siteId) |
| def | recrawlUrlUpdateHandler (self, dbWrapper, recrawlUrlUpdateProperty, urlUpdateObj) |
| def | detectUrlMime (self, contentTypeMap=None, urlObj=None) |
| def | getDepthFromUrl (self, urlMd5) |
| def | updateURLForFailed (self, errorBit, batchItem, httpCode=CONSTS.HTTP_CODE_400, status=dc.EventObjects.URL.STATUS_CRAWLED, updateUdate=True) |
| def | getRealUrl (self) |
| def | resolveHTTP (self, postForms, headersDict) |
| def | updateCrawledURL (self, crawledResource, batchItem, contentSize, status=dc.EventObjects.URL.STATUS_CRAWLED) |
| def | updateURL (self, batchItem, batchId, status=dc.EventObjects.URL.STATUS_CRAWLING) |
| def | updateURLStatus (self, urlId, status=dc.EventObjects.URL.STATUS_CRAWLED) |
| def | resetErrorMask (self, batchItem) |
| def | addURLFromBatchToDB (self, batchItem, crawlerType, recrawlPeriod, autoRemoveProps) |
| def | updateCollectTimeAndMime (self, detectedMime, batchItem, crawledTime, autoDetectMime, httpHeaders=None, strContent=None) |
| def | urlDBSync (self, batchItem, crawlerType, recrawlPeriod, autoRemoveProps) |
| def | updateAdditionProps (self, internalLinksCount, externalLinksCount, batchItem, size, freq, contentMd5) |
| def | createUrlObjForCollectURLs (self, urlMd5, formMethods, parentMd5, depth, detectedMime, maxURLsFromPage) |
| def | createUrlObjForChain (self, pattern, urlMd5, formMethods, parentMd5, depth, detectedMime, maxURLsFromPage) |
| def | updateTypeForURLObjects (self, urlObjects, typeArg=dc.EventObjects.URL.TYPE_CHAIN) |
| def | fillRssFieldInUrlObj (self, oldUrl, objectUrlUlr, batchItem, processorName, feed, rootFeed=False) |
| def | fillRssFieldOneElem (self, entry, urlObj, batchItem, status, crawled, localType) |
| def | urlTemplateApply (self, url, crawlerType, urlTempalteRegular, urlTempalteRealtime, urlTempalteRegularEncode, urlTempalteRealtimeEncode) |
Static Public Member Functions | |
| def | checkDictEmptyStrings (inDict, keys) |
| def | autoRemoveURL (autoRemoveProps, recrawlPeriod, urlTable, wrapper) |
| def | conditionEvaluate (condition, conditionalData) |
| def | additionalUrlObjInit (urlObj, urlInitParam, conditionalData) |
Public Attributes | |
| isUpdateCollection | |
| urlObj | |
| url | |
| dbWrapper | |
| siteId | |
| site | |
| urlTable | |
| protocolsList | |
| siteProperties | |
| normMask | |
Static Public Attributes | |
| string | DC_URLS_TABLE_PREFIX = "urls_" |
| int | DETECT_MIME_TIMEOUT = 1 |
| PATTERN_WITH_PROTOCOL = re.compile('[a-zA-Z]+:(//)?') | |
| string | URL_TEMPLATE_CONST = "%URL%" |
| string | PROTOCOL_PREFIX = "://" |
| list | DEFAULT_PROTOCOLS = ["http", "https"] |
Detailed Description
Definition at line 48 of file URLProcess.py.
Constructor & Destructor Documentation
◆ __init__()
| def dc_crawler.URLProcess.URLProcess.__init__ | ( | self, | |
protocols = None |
|||
| ) |
Definition at line 58 of file URLProcess.py.
Member Function Documentation
◆ additionalUrlObjInit()
|
static |
Definition at line 1061 of file URLProcess.py.
◆ addURLFromBatchToDB()
| def dc_crawler.URLProcess.URLProcess.addURLFromBatchToDB | ( | self, | |
| batchItem, | |||
| crawlerType, | |||
| recrawlPeriod, | |||
| autoRemoveProps | |||
| ) |
Definition at line 567 of file URLProcess.py.

◆ autoRemoveURL()
|
static |
Definition at line 660 of file URLProcess.py.
◆ checkDictEmptyStrings()
|
static |
Definition at line 639 of file URLProcess.py.
◆ checkFieldsIsNone()
| def dc_crawler.URLProcess.URLProcess.checkFieldsIsNone | ( | self, | |
| checkList | |||
| ) |
Definition at line 108 of file URLProcess.py.
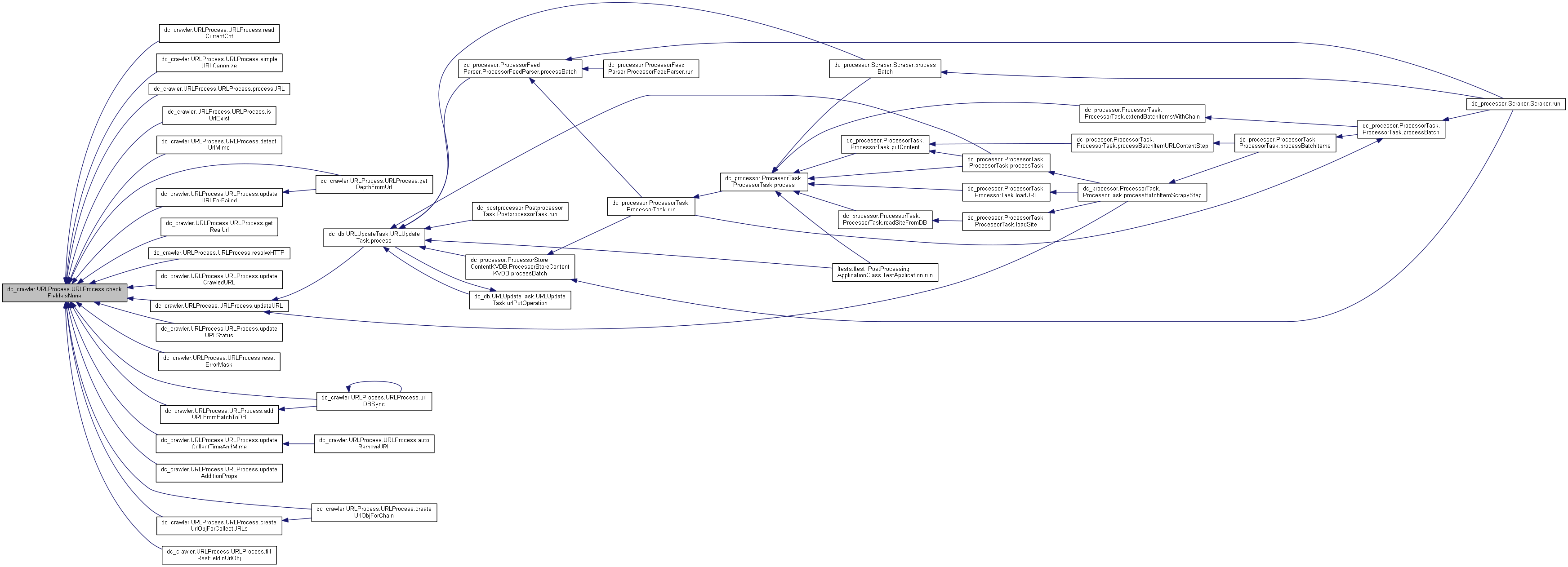
◆ checkUrlByPath()
| def dc_crawler.URLProcess.URLProcess.checkUrlByPath | ( | self, | |
| url | |||
| ) |

◆ checkUrlByProtocol()
| def dc_crawler.URLProcess.URLProcess.checkUrlByProtocol | ( | self, | |
| url | |||
| ) |

◆ conditionEvaluate()
|
static |
Definition at line 1020 of file URLProcess.py.
◆ createUrlObjForChain()
| def dc_crawler.URLProcess.URLProcess.createUrlObjForChain | ( | self, | |
| pattern, | |||
| urlMd5, | |||
| formMethods, | |||
| parentMd5, | |||
| depth, | |||
| detectedMime, | |||
| maxURLsFromPage | |||
| ) |
Definition at line 841 of file URLProcess.py.
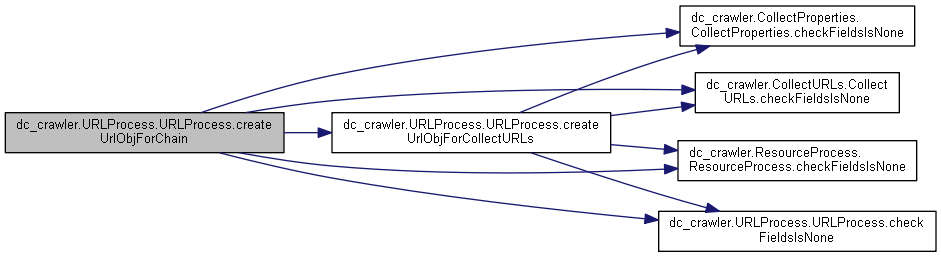
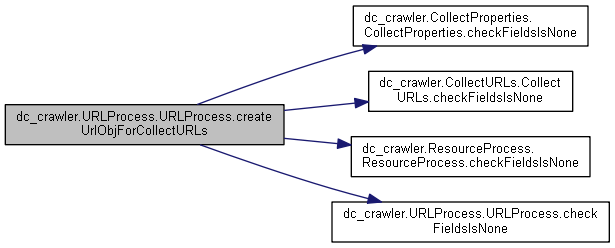
◆ createUrlObjForCollectURLs()
| def dc_crawler.URLProcess.URLProcess.createUrlObjForCollectURLs | ( | self, | |
| urlMd5, | |||
| formMethods, | |||
| parentMd5, | |||
| depth, | |||
| detectedMime, | |||
| maxURLsFromPage | |||
| ) |
Definition at line 809 of file URLProcess.py.

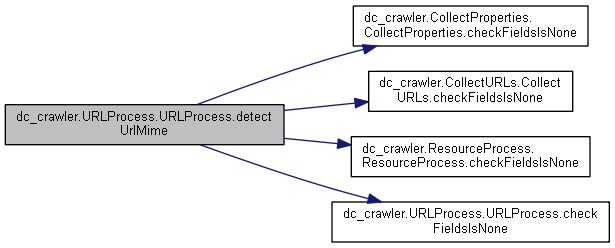
◆ detectUrlMime()
| def dc_crawler.URLProcess.URLProcess.detectUrlMime | ( | self, | |
contentTypeMap = None, |
|||
urlObj = None |
|||
| ) |
◆ fillRssFieldInUrlObj()
| def dc_crawler.URLProcess.URLProcess.fillRssFieldInUrlObj | ( | self, | |
| oldUrl, | |||
| objectUrlUlr, | |||
| batchItem, | |||
| processorName, | |||
| feed, | |||
rootFeed = False |
|||
| ) |
Definition at line 877 of file URLProcess.py.
◆ fillRssFieldOneElem()
| def dc_crawler.URLProcess.URLProcess.fillRssFieldOneElem | ( | self, | |
| entry, | |||
| urlObj, | |||
| batchItem, | |||
| status, | |||
| crawled, | |||
| localType | |||
| ) |
Definition at line 918 of file URLProcess.py.


◆ getDepthFromUrl()
| def dc_crawler.URLProcess.URLProcess.getDepthFromUrl | ( | self, | |
| urlMd5 | |||
| ) |
Definition at line 357 of file URLProcess.py.
◆ getRealUrl()
| def dc_crawler.URLProcess.URLProcess.getRealUrl | ( | self | ) |
◆ isUrlExist()
| def dc_crawler.URLProcess.URLProcess.isUrlExist | ( | self, | |
| recrawlPeriod, | |||
| urlMd5 | |||
| ) |
Definition at line 208 of file URLProcess.py.
◆ processURL()
| def dc_crawler.URLProcess.URLProcess.processURL | ( | self, | |
| realUrl, | |||
| internalLinks, | |||
| externalLinks, | |||
filtersApply = None, |
|||
siteFilters = None, |
|||
baseUrl = None |
|||
| ) |
Definition at line 157 of file URLProcess.py.
◆ readCurrentCnt()
| def dc_crawler.URLProcess.URLProcess.readCurrentCnt | ( | self, | |
| maxURLs | |||
| ) |
Definition at line 126 of file URLProcess.py.
◆ recrawlUrlUpdateHandler()
| def dc_crawler.URLProcess.URLProcess.recrawlUrlUpdateHandler | ( | self, | |
| dbWrapper, | |||
| recrawlUrlUpdateProperty, | |||
| urlUpdateObj | |||
| ) |

◆ resetErrorMask()
| def dc_crawler.URLProcess.URLProcess.resetErrorMask | ( | self, | |
| batchItem | |||
| ) |
Definition at line 550 of file URLProcess.py.
◆ resolveHTTP()
| def dc_crawler.URLProcess.URLProcess.resolveHTTP | ( | self, | |
| postForms, | |||
| headersDict | |||
| ) |
Definition at line 425 of file URLProcess.py.
◆ resolveTableName()
| def dc_crawler.URLProcess.URLProcess.resolveTableName | ( | self, | |
| localSiteId | |||
| ) |
Definition at line 119 of file URLProcess.py.
◆ setProtocols()
| def dc_crawler.URLProcess.URLProcess.setProtocols | ( | self, | |
protocols = None |
|||
| ) |
Definition at line 74 of file URLProcess.py.
◆ simpleURLCanonize()
| def dc_crawler.URLProcess.URLProcess.simpleURLCanonize | ( | self, | |
| realUrl | |||
| ) |
◆ updateAdditionProps()
| def dc_crawler.URLProcess.URLProcess.updateAdditionProps | ( | self, | |
| internalLinksCount, | |||
| externalLinksCount, | |||
| batchItem, | |||
| size, | |||
| freq, | |||
| contentMd5 | |||
| ) |
Definition at line 787 of file URLProcess.py.
◆ updateCollectTimeAndMime()
| def dc_crawler.URLProcess.URLProcess.updateCollectTimeAndMime | ( | self, | |
| detectedMime, | |||
| batchItem, | |||
| crawledTime, | |||
| autoDetectMime, | |||
httpHeaders = None, |
|||
strContent = None |
|||
| ) |
Definition at line 714 of file URLProcess.py.

◆ updateCrawledURL()
| def dc_crawler.URLProcess.URLProcess.updateCrawledURL | ( | self, | |
| crawledResource, | |||
| batchItem, | |||
| contentSize, | |||
status = dc.EventObjects.URL.STATUS_CRAWLED |
|||
| ) |
Definition at line 448 of file URLProcess.py.
◆ updateTypeForURLObjects()
| def dc_crawler.URLProcess.URLProcess.updateTypeForURLObjects | ( | self, | |
| urlObjects, | |||
typeArg = dc.EventObjects.URL.TYPE_CHAIN |
|||
| ) |
Definition at line 855 of file URLProcess.py.
◆ updateURL()
| def dc_crawler.URLProcess.URLProcess.updateURL | ( | self, | |
| batchItem, | |||
| batchId, | |||
status = dc.EventObjects.URL.STATUS_CRAWLING |
|||
| ) |
Definition at line 505 of file URLProcess.py.
◆ updateURLFields()
| def dc_crawler.URLProcess.URLProcess.updateURLFields | ( | self, | |
| urlMd5, | |||
| wrapper, | |||
| siteId | |||
| ) |
Definition at line 242 of file URLProcess.py.


◆ updateURLForFailed()
| def dc_crawler.URLProcess.URLProcess.updateURLForFailed | ( | self, | |
| errorBit, | |||
| batchItem, | |||
httpCode = CONSTS.HTTP_CODE_400, |
|||
status = dc.EventObjects.URL.STATUS_CRAWLED, |
|||
updateUdate = True |
|||
| ) |
Definition at line 375 of file URLProcess.py.

◆ updateURLStatus()
| def dc_crawler.URLProcess.URLProcess.updateURLStatus | ( | self, | |
| urlId, | |||
status = dc.EventObjects.URL.STATUS_CRAWLED |
|||
| ) |
Definition at line 537 of file URLProcess.py.
◆ urlDBSync()
| def dc_crawler.URLProcess.URLProcess.urlDBSync | ( | self, | |
| batchItem, | |||
| crawlerType, | |||
| recrawlPeriod, | |||
| autoRemoveProps | |||
| ) |
Definition at line 746 of file URLProcess.py.
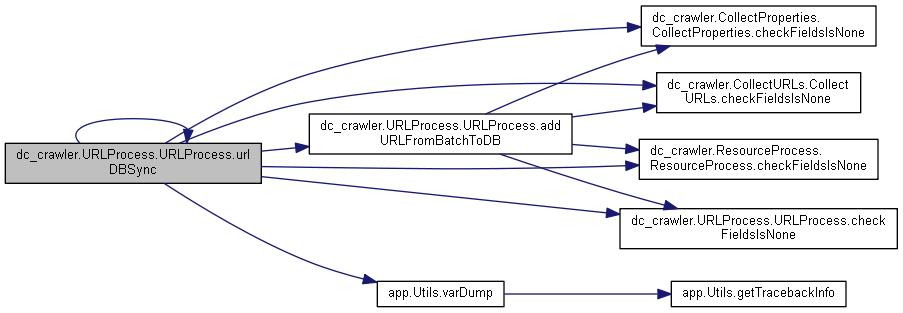
◆ urlTemplateApply()
| def dc_crawler.URLProcess.URLProcess.urlTemplateApply | ( | self, | |
| url, | |||
| crawlerType, | |||
| urlTempalteRegular, | |||
| urlTempalteRealtime, | |||
| urlTempalteRegularEncode, | |||
| urlTempalteRealtimeEncode | |||
| ) |

Member Data Documentation
◆ dbWrapper
| dc_crawler.URLProcess.URLProcess.dbWrapper |
Definition at line 62 of file URLProcess.py.
◆ DC_URLS_TABLE_PREFIX
|
static |
Definition at line 50 of file URLProcess.py.
◆ DEFAULT_PROTOCOLS
|
static |
Definition at line 55 of file URLProcess.py.
◆ DETECT_MIME_TIMEOUT
|
static |
Definition at line 51 of file URLProcess.py.
◆ isUpdateCollection
| dc_crawler.URLProcess.URLProcess.isUpdateCollection |
Definition at line 59 of file URLProcess.py.
◆ normMask
| dc_crawler.URLProcess.URLProcess.normMask |
Definition at line 69 of file URLProcess.py.
◆ PATTERN_WITH_PROTOCOL
|
static |
Definition at line 52 of file URLProcess.py.
◆ PROTOCOL_PREFIX
|
static |
Definition at line 54 of file URLProcess.py.
◆ protocolsList
| dc_crawler.URLProcess.URLProcess.protocolsList |
Definition at line 66 of file URLProcess.py.
◆ site
| dc_crawler.URLProcess.URLProcess.site |
Definition at line 64 of file URLProcess.py.
◆ siteId
| dc_crawler.URLProcess.URLProcess.siteId |
Definition at line 63 of file URLProcess.py.
◆ siteProperties
| dc_crawler.URLProcess.URLProcess.siteProperties |
Definition at line 67 of file URLProcess.py.
◆ url
| dc_crawler.URLProcess.URLProcess.url |
Definition at line 61 of file URLProcess.py.
◆ URL_TEMPLATE_CONST
|
static |
Definition at line 53 of file URLProcess.py.
◆ urlObj
| dc_crawler.URLProcess.URLProcess.urlObj |
Definition at line 60 of file URLProcess.py.
◆ urlTable
| dc_crawler.URLProcess.URLProcess.urlTable |
Definition at line 65 of file URLProcess.py.
The documentation for this class was generated from the following file:
- sources/hce/dc_crawler/URLProcess.py
- Generated on Fri Nov 24 2017 18:54:35 for HCE Project Python language Distributed Tasks Manager Application, Distributed Crawler Application and client API bindings. by
 1.8.13
1.8.13