Introduction
This article shows main basic principles of general internal architecture and algorithms for newcomers to help to understand better the usability advantages and potential efficiency of HCE. For project architects, system integrators, general architecture design engineers, team leaders and technical management staff this information will help to understand better the possible place and role of HCE as engine and tool in the target project, to imagine the potential goals and possible to answer on several general questions about possible integration…
The HCE as engine has core architecture that represents main feature – to construct, build and hold network cluster infrastructure based on ZMQ PPP transport protocol that lays on TCP under Linux OS and is core on system-layer.
The HCE as framework has set API binding on user’s layer functionality. Common layers of architectural components can be represented as:

Networking and threading
Cluster core implemented on POSIX multi-thread computation parallelism and distributed multi-host requests processing on MOM-based networking model.
Main cluster infrastructure based on different roles of nodes, separated data and admin requests handling by using two dedicated ports, asynchronous messages handling and processing based on ZMQ inproc sockets. Also is ready to be transactional and redundant.
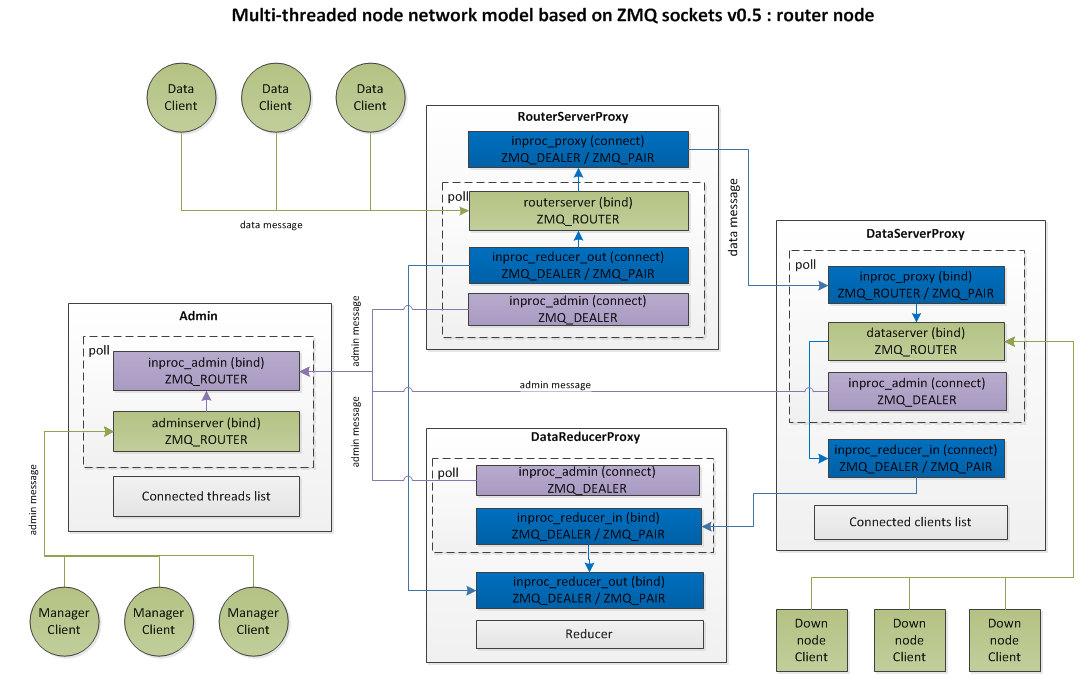
The concrete internal threading architecture and messages routing model of HCE node instance depends on role is static and can be one of router, manager or data that is defined on start.
Messages routing of data requests messages for descent flows as well as messages collecting algorithm and reduce data processing for ascent flows depends on manager node mode – shard or replica.
Router mode
Manager mode

Data mode

Passive health checks
All kind of node roles instances doing the bidirectional heartbeating algorithm. There several types of behavior and parametrized cycling can be configured to make liveness and responsibility of nodes more strong and flexible. All timeouts and delays are configurable at start and run-time.
Dead Node Detection
If a node stops responding, it will be marked as dead for a configurable amount of time. The dead nodes will be temporarily removed from the load-balancing rotation on server node and client will enter in cycle of tries to re-connect to server node in case of it was marked as dead.